


If 2023 was the year of "Wow, it can talk," and 2024 was the year of "Let's put a chatbot on everything," then 2025 was the year of the chatbot hangover.
Why did it happen? Enterprises scrambled to deploy conversational interfaces that could recite company policy with poetic flair. However, these chatbots couldn't execute a single meaningful business process. The end result? A terrible user experience.
For the past two years, most teams have shipped “AI features.” However, in 2026, businesses are asking a tougher question: "Can this system actually complete work reliably inside my business?"
That’s the real shift. We are no longer building software that retrieves information. We are building software that owns outcomes with Agentic AI. So, what essentially changes?
This Article Contains:
Chatbot vs. AI Agent: What's the difference?
The confusion between chatbots and agents usually stems from the fact that they share the same interface (a text box). But functionally, they are distinct species. While a chatbot is optimized to respond, an agentic system decides, acts, recovers, and escalates.
A clearer way to understand the difference between a chatbot and an AI agent is to run it through a workflow test.
Ask the system to:
Close a support ticket, verify whether the SLA was breached, calculate refund eligibility, draft the transaction, and escalate if the threshold is exceeded.
A traditional chatbot can explain the SLA policy. It can summarize refund rules. It may even generate a well-written response to the customer.
But it cannot reliably:
Check ticket timestamps against SLA commitments
Pull billing data from internal systems
Apply refund logic under policy constraints
Stage a financial transaction
Escalate based on approval thresholds
Maintain a traceable audit log of what happened and why
A chatbot generates answers about the workflow. An agentic system executes the workflow. That’s the difference.
The dividing line is not intelligence or fluency. It is architecture. Can the system operate across tools and services (like your ERP, CRM, etc.), enforce permissions, recover from failure, and produce traceable outcomes inside your business?
If the answer is no, you don’t have an operational agent yet. You have a conversational interface with integrations.
This happens because a chatbot, powered by a Large Language Model (LLM), is nothing more than a probabilistic text generator. It does not have an agency to do something and can only predict the next token.
Note: A large language model does not understand in terms of characters. It typically compresses information in the form of tokens, such as "fr", "ab", and "ous". Using this approach, "Frabjous Day" compresses to five tokens ("Fr", "ab", "j", "ous", " Day") instead of 12 individual characters.
This ability to predict a token makes it look like it can think, reason, and act. In reality, it's just clubbing sentence fragments together based on how likely the next chunk is to appear based on the chunks already present in the context window.
On the other hand, an agentic AI, if its guardrails permit, can find the date today by using a set of commands (generally called "tool calls").
The agent recognizes that it cannot answer the question with its internal weights, so it pauses generation, executes a Python script or an API call to get_current_date(), retrieves the current date, and then generates the final answer while adding the received date into its context.
In a nutshell, chatbots retrieve the information they're trained on while agents execute. A chatbot is a conversational layer, while an AI agent is an operational layer.
Yet, to be fair, in 2026, the line can blur a little. Many “chatbots” now have tool access. The real divider now is "Can the system reliably run a business task end-to-end under constraints?"
That’s where most teams hit the wall.
A tool-calling chatbot is not a production agent
Many systems marketed as agents are still just chatbots with one or two API integrations. They can do a flashy demo on the happy path, but fail the moment reality gets messy.
A production-grade agent must do four things consistently:
1. Decide with constraints
Not just “what’s the best next step?" but “what’s the best next step given policy, permissions, SLAs, and risk?”
2. Act with bounded authority
It should only be able to call approved tools, with least privilege, without hindering its ability to answer the queries within scoped limits.
3. Recover when things break
Timeout? Missing field? API mismatch? It should retry intelligently, choose fallbacks, or escalate to a human.
4. Prove what happened
Every meaningful step must be traceable, like what was decided, what tool was called, what changed, and why.
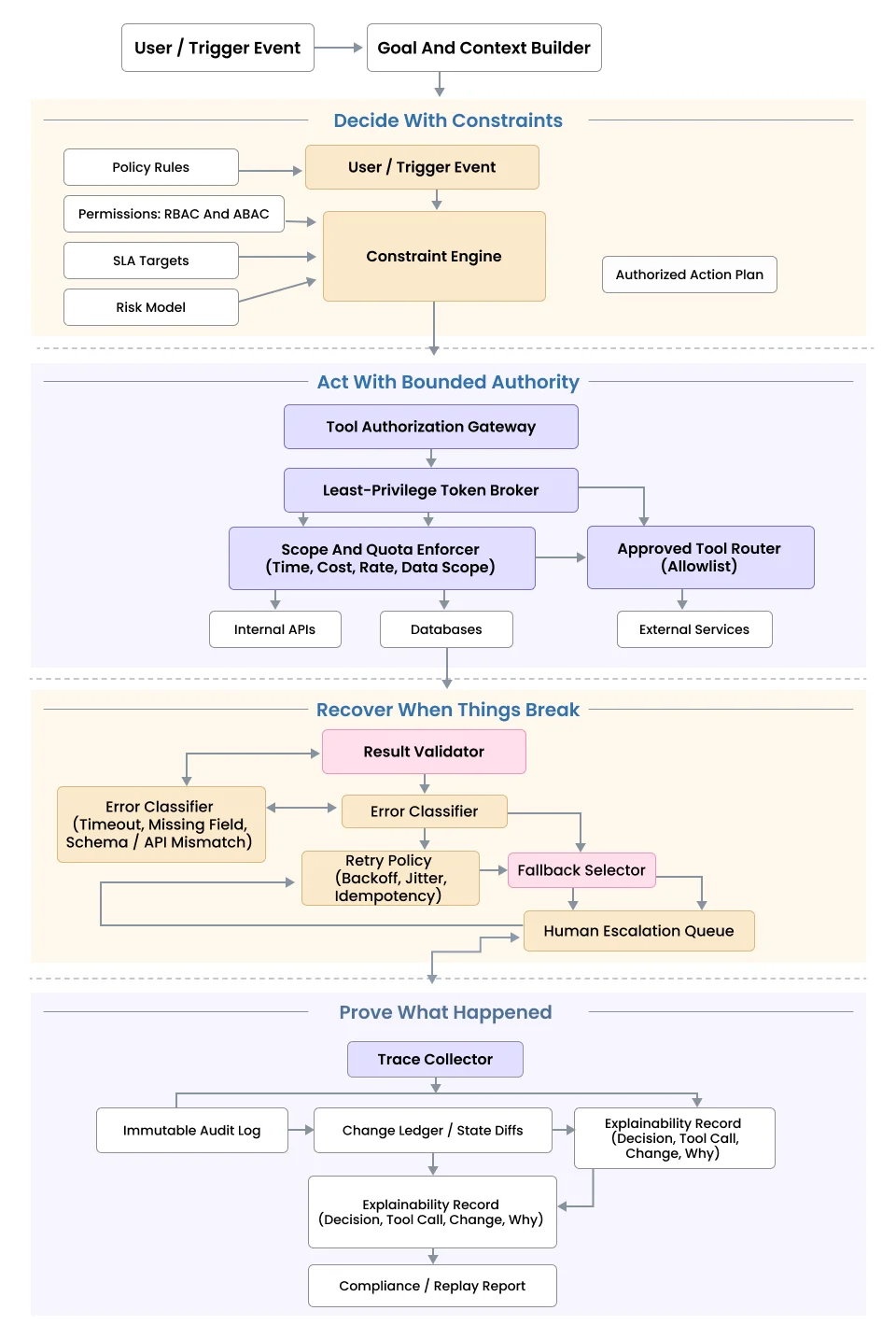
If your system cannot do those four things, it is not an operational agent yet. It is still a conversational assistant with integrations.
1. The "Moltbook" lesson: Why prototypes are not production
If you need proof of how messy it can get, look no further than the Moltbook Incident that happened recently, which exposed 1.5 million API keys.
The viral "agent social network" promised a world of autonomous interaction. It collapsed almost instantly. Why? Not because the AI wasn't smart, but because the Identity Architecture was nonexistent. Millions of agents were hijacked because they lacked proper authentication layers. They were "vibe-coded" prototypes pushed into production without security governance.
In enterprise development, we don't build "autonomous" agents; we build Bounded Agents. To do so, we have to change the fundamental software architecture.
From linear chains to cognitive loops
To understand why an agent can do work that a chatbot can't and why it introduces new risks, you have to look at the control flow.
Standard chatbots operate on a "Fire-and-Forget" model.
1. The user asks a question.
2. Bot retrieves data.
3. The bot generates an answer.
4. Process Ends.
This architecture is brittle. If the bot retrieves the wrong data, it has no way to know. It just hallucinates an answer and closes the ticket. It has no "inner monologue" to double-check its work. At the same time, it's open to prompt injection or malicious code insertions/execution, which it cannot validate in the absence of a hard security layer.
Agentic systems run on a Control Loop, often modeled after the OODA Loop (Observe, Orient, Decide, Act). This is the heartbeat of modern automation:
1. Observe: The agent reads the user's intent ("Fix the bug") and the current environment (the codebase).
2. Orient: It also validates the input against security signatures to ensure it isn't processing a jailbreak attempt.
3. Decide: It formulates a plan. “I need to write a test case, fail it, patch the code, and pass it.” Simultaneously, it runs a Policy Check: "Does this user have 'Write' permissions for this repository?" If the intent violates policy, the plan shifts to a denial.
4. Act: It executes the first step (writing the test). If the policy check fails, it executes a Security Denial event, logging the attempt and informing the user. The agent looks at the result. "Did the test fail as expected? Did the API return a 403 Forbidden?" It then restarts or exits the loop as required.
This Reflection Pattern is the difference between a prototype and a product. A chatbot fails silently; an agent observes the failure and attempts to recover.
Adding Human-in-the-Loop (HITL)
However, this cognitive loop introduces a new danger. If you give an AI the ability to "Act" and "Retry" without supervision, you risk it spiraling out of control. This can be especially detrimental when anything material, like a financial transaction, is associated with the workflow.
We solve this by decoupling Reasoning from Commitment. We use a "Draft & Approve" Pattern.
Instead of letting an agent execute high-stakes actions directly, we implement deterministic pipelines and state machines with schema validations, logic gates, and rigid templating. For critical workflows, this rigid templating necessitates human involvement for the final go-ahead.
1. The Trigger: A user writes, "Issue a refund for Order #1234."
2. The Reasoning: The agent validates the policy. "Condition met."
3. The Staging: The agent does NOT call the Stripe refund API. Instead, it creates a staged payload:
{
"action": "refund",
"amount": 49.99,
"reason": "Damaged Goods",
"status": "AWAITING_APPROVAL"
}
4. The Handoff: The agent pauses its execution loop. It pings a human support manager: "I have prepared a refund. Please approve." It also hard stops if it retries and fails a preset number of times, avoiding infinite loops.
5. The Execution: Only after the human clicks "Approve" does the agent resume and fire the API.
This is the shift from prototype to production. We aren't replacing human judgment. We are simply removing human drudgery.
In agentic AI systems, the biggest challenge is not configuring (or even misconfiguring) the workflow. It's the sheer amount of edge cases that arise during the agent operation. Some of them include prompt injection, unauthorized tool access, and "infinite loop" scenarios where an agent burns through your API budget trying to fix a bug it essentially can't solve.
The first line of defense is to implement safeguards, such as scoped tool permissions, execution limits, prompt-injection filters, and budget caps. But safeguards alone are not enough. A robust fallback system should detect when the agent is stuck, uncertain, or operating outside expected boundaries, then either switch to a safer recovery path or pause the workflow.
Some cases should trigger immediate escalation such as repeated failed attempts, requests for unauthorized data or tools, suspected prompt injection, unexpected spending spikes, irreversible actions, or decisions involving legal, financial, or customer-impacting consequences. In these situations, human-in-the-loop is the only control layer that keeps autonomous systems 100% reliable, auditable, and safe.
1. The integration shift to MCPs
For years, connecting an LLM to a database meant writing brittle "glue code" for every API. If Salesforce changed a field name, your bot broke.
In 2026, we use the Model Context Protocol (MCP). Think of MCP as a uniform connector that allows your agent to understand how to use an external service (or changing APIs) without explicitly hardcoding them into your context. MCP, as an open standard, lets you expose your data (Google Drive, Slack, PostgreSQL, etc.) to any agent.
Instead of hard-coding API wrappers, you install a standard MCP server, and the agent immediately sees the tools available (search_customer, update_record, etc.) without custom code.
MCPs also help you prevent vendor lock-in by making your codebase and relevant architecture more aligned with the Dependency Inversion Principle. You can swap out the underlying brain (e.g., moving from GPT-5.2 to Claude 4.6) without rewriting your integrations because the MCP layer remains constant.
2. The ROI of "Doing" vs. "Talking"
Why are companies shifting their budget from chatbots to agents? Chatbots deflect tickets, but agents resolve them.
As an example, a user asks, "Where do I send this invoice?" The bot replies, "Please email [email protected]."
With agentic AI, the agent extracts data from the PDF and matches the invoice against open Purchase Orders in QuickBooks. It then thinks, "The amounts match, but the vendor address is different from our records. Flagging for review."
It validates if the user is authenticated and alerts regarding the same, requesting clarification. The agent then accepts the invoice, drafts the payment in the banking portal, and prompts the CFO for final sign-off along with relevant notes.
This approach not only keeps the email account clutter-free but also ensures that the CFO and everyone involved save countless hours while making informed decisions at speed and scale.
Building a workforce, not just a Wiki
The shift to Agentic AI is the difference between hiring a consultant who gives you advice and hiring an employee who does the work.
In 2026, the competitive advantage belongs to companies that can successfully delegate complex workflows to AI. But delegation requires trust, and trust requires the "sane" architecture we've discussed: Bounded Autonomy, Standardized Tools (MCP), and Stateful Memory.
However, an agent is only as intelligent as the context it holds. If you send a brilliant agent to work without giving it access to your company's history, rules, and data, it will fail.
To build a reliable agent, you must also solve the "Knowledge" problem. In our next post, we will dive into RAG Systems 101: How to Give an Agent Reliable Company Context. Stay tuned and make sure to join our mailing list!
Frequently Asked Questions
Unlike chatbots, which primarily carry reputational risks (e.g., hallucinating offensive text), agentic systems introduce operational risks because they can execute real transactions, modify databases, and trigger workflows. This requires a fundamental shift from simple content moderation to strict "transaction logic" governance, often necessitating new insurance assessments and tighter collaboration between engineering and legal teams to define the specific boundaries of the agent's authority.
Yes, on a per-interaction basis, but likely not on a per-resolution basis. While a chatbot provides a cheap, single-turn response, an agent runs a "cognitive loop" that may trigger multiple internal API calls and reasoning steps. However, the financial metric shifts from minimizing "cost per message" to reducing the much higher "total cost of resolution" currently borne by companies.
Absolutely, because agents require structured interfaces to function reliably, whereas chatbots can often survive on messy, unstructured text like PDFs and wikis. To enable an agent to "do" work, like paying an invoice or updating a CRM record, companies must often clean up their internal APIs and data schemas first, ensuring the agent has reliable, structured "handles" to interact with rather than just vague documents to summarize.
This architecture shifts the role of human employees from "doers" to "auditors." As agents handle the initial drudgery of drafting responses or staging transactions, the demand for entry-level support staff to manually execute tasks decreases, while the need for subject matter experts increases. These experts are needed to review and approve the complex "drafts" generated by the AI, transforming the job into one of high-level verification and quality control rather than manual execution.



