


Today, almost everyone explains what an AI agent is with poetic flair. What rarely gets explained is the part that decides whether a deployment survives contact with a real business.
Where does each component live in a real system, who controls it, and what actually happens when something goes wrong?
That is where production programs either succeed or fail.
If you want business outcomes from agentic AI, treat it like a functional system with control points. This blog is a practical map of those control points and how they behave at runtime.
This Article Contains:
What shift businesses are dealing with right now?
In 2025 and 2026, enterprises moved from "Can AI answer this?" to "Can AI execute this safely?"
The upside is real. PwC's 2025 Global AI Jobs Barometer points to strong productivity and wage signals in AI-exposed roles and industries.
The failure rate is also real. Gartner reported in mid-2025 that more than 40% of agentic AI projects are likely to be canceled by the end of 2027 due to cost, unclear value, or weak risk controls.
Rather than being contradictory signals, they are the same signal seen from two different angles. Value is available, but control maturity becomes the bottleneck.
This is also why accountability becomes a serious part of architecture. In Moffatt v. Air Canada, 2024 BCCRT 149, the tribunal held Air Canada liable for misinformation provided by its chatbot. If liability does not disappear for informational output, it definitely does not disappear when systems can trigger transactions.
What does "agentic system" mean in operational terms?
A useful practical definition is that an agentic system is a runtime that can:
Interpret a goal.
Pull the right context.
Plan the next steps.
Use tools to act.
Check what happened.
Recover or escalate.
Produce a trace that humans can audit.
If one of these is missing, you do not have a production-grade AI agent. You can call what you have a useful assistant. The two have very different risk profiles.
The 12 components of Agentic AI
The architecture we use in practice has 12 components:
Objective and Policy Layer
Task Intake Layer
Perception Layer
Knowledge and Retrieval Layer
Memory Layer
Reasoning and Planning Layer
Tooling Layer
Orchestration and Control Loop Layer
Action and Execution Layer
Coordination Layer (optional multi-agent)
Safety, Security, and Governance Layer
Observability and Evaluation Layer
The difference is not whether you have these building blocks. It is whether they are controlled as enforceable runtime boundaries once the agent can read sensitive data or write to production systems.
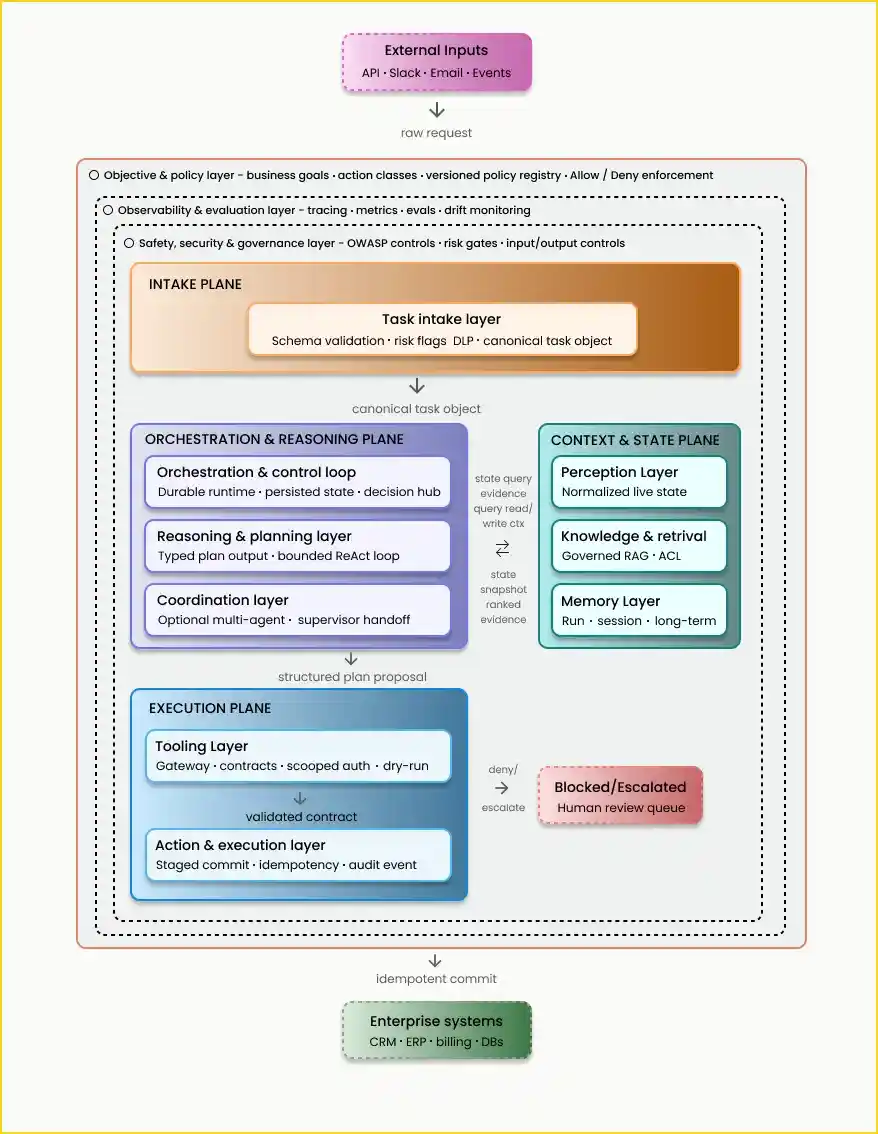
Let us discuss each component as a software boundary with control behavior.
1. Objective and Policy Layer
The Objective and Policy layer acts as the enterprise's 'bouncer' for your AI. It intercepts what the AI plans to do and checks it against hardcoded business rules before any external system is touched. What we get as the end result is a strict 'Allow' or 'Deny' signal. If allowed, it generates a verifiable "approval token" that the system must use to execute an action. If denied, the execution is killed before it starts.
The Objective and Policy layer resides in your control plane, where business goals are transformed into enforceable runtime rules. While teams initially write policies into prompts, high-stakes workflows require moving these boundaries into versioned, testable policy registries. Prompts shape behavior but are not authorization systems. As indicated by the OWASP Top 10 for LLM Applications 2025, you must strictly constrain an LLM's action capabilities to prevent 'excessive agency' failures.
The layer primarily defines action classes, such as:
Class A: Read-only retrieval (view customer record)
Class B: Reversible writes (draft ticket update)
Class C: Financial or legal write requiring approval (issue refund, modify policy)
Class D: Hard-deny actions (delete financial records)
In practical deployments, this layer consists of three concrete components:
A version-controlled registry for objectives, action classes, and exceptions.
A decision service that evaluates the policy (such as the principal, action, or context) to return a deterministic allow or deny.
A runtime enforcement boundary that permits or blocks tool execution based on that decision.
In enterprise setups, this enforcement boundary is a tool gateway configured to strictly fail closed on missing approvals, scopes, or policy decisions.
Two common implementation patterns include:
Policy-as-code engines as a decision service, such as Open Policy Agent.
Authorization engines with explicit Allow or Deny outcomes, such as the Cedar authorization model.
The critical design detail here is decoupling. While the policy engine makes the decision, the runtime boundary enforces it. Also, enforcement must occur strictly outside the model loop, directly at the APIs and commit endpoints. Prompts must not bind the runtime. Otherwise, the agent may likely overstep, especially during long-running tasks.
2. Task Intake Layer
People hear 'intake' and assume it is trivial RAG-based parsing; It is simple text retrieval or prompt preprocessing, it is a critical normalization and validation step in production agent systems. In practice, this is where many high-cost mistakes begin.
Incoming messages are not only chat messages. They are email requests, CRM tasks, support tickets, Slack or Teams messages, and API-triggered events.
The intake layer usually sits behind an API gateway as an ingestion service (for example, Kong Gateway). Its job is to convert heterogeneous input into a canonical task object. That object commonly includes intent, entities, confidence, urgency, risk flags, and the requested action class. In many stacks, the canonical task object is also persisted and published to a queue so orchestration can run asynchronously with retries, backoff, and clear ownership for failures.
This conversion happens in a deterministic extraction step that combines model output with strict schema validation. A common stack looks like this:
Model extraction using a function or tool calling (OpenAI function calling guide).
Structured output constrained to JSON schema (OpenAI structured outputs guide).
Server-side validation via typed schema libraries.
Confidence thresholds and ambiguity routing for low-certainty tasks.
Human-review gates for high-risk action classes.
Rule-based risk enrichment before orchestration, including sensitivity flags and DLP checks aligned with your enterprise controls (for example, Microsoft Purview DLP overview).
This is the point many intermediate agent stacks skip. They have an agent loop and tools, but their intake is still free-form, making them vulnerable to prompt injection. The practical upgrade is to treat intake as a contract boundary, so downstream orchestration can refuse to proceed when fields are missing, ambiguous, or high-risk.
For instance, a normalization failure will look something like this:
Vendor name extracted, but legal entity missing.
Currency parsed without locale context.
The invoice is flagged urgent, but there's no policy basis.
The request asks for "refund" but lacks a transaction identifier.
In mature systems, orchestration does not proceed when required task fields are missing. It requests clarification or routes to human triage.
That one gate often saves weeks of incident cleanup in enterprise rollouts.
3. Perception Layer
The perception layer usually lives in your integration plane between the orchestrator and your systems of record, like databases, CRM, HRIS, CMDB, etc. At runtime, the orchestrator requests Perception for a state snapshot. This layer reaches out to ERP, CRM, ticketing, identity, payments, and case systems, then returns a normalized state with timestamps and source IDs.
If the orchestrator asks the Perception layer for the state of "User A", instead of getting five different, confusing responses from five different APIs, it gets one neat payload that looks something like this:
{
"entity_id": "USER-9981",
"state": {
"user_name": {
"value": "Jane Doe",
"source_system": "HRIS_Workday",
"source_id": "WD-7721",
"fetched_at": "2026-03-18T09:15:00Z",
"version": "2"
},
"email": {
"value": "[email protected]",
"source_system": "Identity_Okta",
"source_id": "OK-991A",
"fetched_at": "2026-03-18T09:15:02Z",
"version": "5"
},
"account_balance": {
"value": 450.00,
"source_system": "Billing_Stripe",
"source_id": "CUS-44919",
"fetched_at": "2026-03-17T14:20:00Z",
"version": "12"
}
}
}
In production systems, this is typically implemented with API connectors, webhook consumers, and change-data-capture feeds so that state can be refreshed continuously instead of on batch intervals. You will commonly see queue-based consumers for event ingestion, plus a cache with strict TTL for hot reads. Some teams implement connectors as Model Context Protocol servers that wrap internal APIs and standardize authentication, schema, and observability across tools.
The operational controls that matter here are practical. For example,
Every state field includes source_system, fetched_at, and version.
Freshness SLA is defined per field.
If the freshness SLA is breached, orchestration moves to refresh or escalate, not execute.
Conflicting states from two systems are resolved by a precedence policy and not by model guesswork.
The layer distinguishes between null, unknown, and unavailable values.
Units, timestamps, currencies, and identifiers are normalized before use.
Without this layer, an agent can follow the policy perfectly and still fail the business process because it acted on stale data.
4. Knowledge and Retrieval Layer
This is where RAG either becomes governance infrastructure or remains a nice demo.
In production, retrieval is usually a dedicated service with its own ingestion jobs, indexing pipeline, Access Control List (ACL) logic, document versioning, freshness SLAs, and continuous quality evaluation.
Ingestion jobs continuously monitor source systems for new or updated content, enforce freshness requirements, and trigger reprocessing before the ingestion pipeline parses files, chunks content, enriches metadata, creates embeddings, and writes to one or more indexes.This is also where many teams standardize on a retrieval framework to avoid rewriting glue code across agents (for example, agent tooling patterns in LlamaIndex).
Real systems typically use hybrid retrieval, including lexical and semantic, then rerank. This is because semantic similarity alone often returns text that is linguistically close but operationally incorrect. Where relevant, you can use search platforms, like Elastic hybrid search and OpenSearch hybrid search, position hybrid retrieval, and reranking as first-class building blocks.
Remember, ACL is critical here. If permission filtering happens after retrieval, you would have already leaked signals. Mature systems filter access before ranking, so unauthorized chunks never enter the candidate set.
Document versioning and freshness SLAs are closely related to this. The retriever should know which version of a document is current, which version was used to generate an answer, and how quickly updates from source systems must appear in the index. Without this, an agent may cite an outdated policy, miss a newly updated support article, or answer from a document that should have been superseded.
Continuous quality evaluation closes the loop. Teams should regularly test whether retrieval returns the right authorized evidence, ranks authoritative sources above weaker matches, avoids stale documents, and preserves citation accuracy. In production, retrieval quality should be monitored like any other critical system dependency.
Another production detail teams miss is context packing. "Lost in the Middle" effects are real in long prompts. If high-value evidence is buried, answer quality drops even if a retrieval is correct. That is why ranking quality and evidence ordering often matter more than context window size.
5. Memory Layer
In practice, there are three memory tiers.
Run memory: It offers the ephemeral state for the current execution.
Session memory: Session memory provides continuity for a user or case over a short horizon.
Long-term memory: These are the approved summaries, decision logs, or preferences with governance.
Run memory usually sits directly within the orchestrator's state management (such as Temporal or AWS Step Functions), temporarily holding intermediate variables and execution graphs until the specific task completes.
Session memory often resides in low-latency caches like Redis or fast relational tables configured with strict Time-To-Live (TTL) limits. It helps in bridging context across multiple runs for an active interaction before automatically expiring.
Long-term memory is typically persisted in specialized, governed stores, such as vector databases for semantic retrieval or encrypted tables, that enforce strict access controls, audit trails, and automated retention or deletion policies for compliance.
Since memory is not singular, if you do not separate your memory types, you create silent reliability risks. The control rule is also simple but non-negotiable. Memory can inform, but memory cannot override the system of record.
Write discipline matters just as much. Do not let every model output write to long-term memory. Also, use explicit memory-write policies. For example, write only after successful completion, human approval, or repeated confirmation. Without these controls, memory drifts, contradicts current truth, and contaminates future decisions.
6. Reasoning and Planning Layer
This layer decides what should happen next, but it must not decide what can be committed. This separation is where production reliability starts.
In most mature systems, the planner runs as a bounded service behind the orchestrator. It receives the normalized task object, live state snapshot, retrieved evidence, and policy class as structured inputs. Instead of returning an open-ended, conversational text response, it then returns a strongly typed, deterministic plan. This plan is a strict, machine-readable data structure (typically enforced via JSON Schema or Pydantic) that can be translated directly to the orchestrator's execution graph.
A practical plan payload usually includes step_id, required_inputs, tool_candidate, risk_class, expected_outcome, and fallback_step.
Before execution, the plan validator checks schema validity, tool availability, policy compatibility, and missing prerequisites. Only then does the orchestrator execute step one.
Once execution begins, the system may rely on ReAct-style loops that are useful here for iterative thinking and tool use, but the runtime must cap them in production with max steps per run, max retries by error category, max token budget, and forced escalation thresholds. Open Web Application Security Project explicitly calls out unbounded consumption risk in LLM applications, and these caps are one of the direct mitigations. Without these limits, planners drift into expensive loops that look intelligent but do not converge.
7. Tooling Layer
Tooling is the execution gateway into your business systems. This is also where the highest blast radius exists.
In a production environment, tools are not exposed directly to the model. They are registered in a tool gateway that enforces schema, authorization scope, rate limits, idempotency policy, and audit logging.
A practical tool contract includes a strict input schema, a strict output schema, a side-effect type (read, reversible write, irreversible write, etc.), retry behavior, a required policy class, and a timeout, as well as a fallback route.
Whether you use function calling (OpenAI function calling guide), plugins and skills (Agent Skills, Semantic Kernel plugins, etc.), or MCP (Model Context Protocol specification, OpenAI MCP and connectors), treat them as integration interfaces, not authorization boundaries. In other words, these standards help you wire tools to models, but the 'can this run' decision still has to be enforced at your tool gateways and your endpoints.
That one distinction is what prevents 'the model had access' from turning into 'the model had authority.'
Note: For write-capable tools, dry_run support is a good pattern to have. It lets the system simulate impact and preflight validations even before commit endpoints are touched.
8. Orchestration and Control Loop Layer
This is the runtime spine, because without orchestration, an agent becomes a chain of prompts rather than a controlled execution system.
The difference shows up when something goes wrong. Without orchestration, a failed tool call, missing approval, timeout, or bad intermediate result often sends the agent back into another prompt attempt with little memory of what was safely completed.
With an orchestrator, the system has a control loop, which can persist state, detect failure modes, retry only safe steps, route to a fallback path, escalate to a human, and resume from the right checkpoint.
In production, the orchestrator layer runs in a durable workflow infrastructure with persisted state and deterministic resume. This is why workflow runtimes like Temporal, state machines like AWS Step Functions, and checkpointed graph execution like LangGraph and LangGraph persistence exist. When the process crashes, you resume from a checkpoint rather than re-running prior steps and risking duplicate side effects.
A robust control loop usually has explicit states such as received, normalized, planned, awaiting approval, executing, verifying, completed, failed, and escalated.
But why does this matter in business workflows? Because a process that pauses for approval at 3 AM should resume safely at 9 AM once that approval is received. It should continue without duplicated actions and without losing context.
Retry policy also has to be error-aware. Your workflow must retry timeouts and transient network failures. It must not retry policy denials, schema failures, or explicit business-rule violations.
9. Action and Execution Layer
As the name implies, business consequences become real in this layer with money movements, record changes, and customer outcomes.
Because these operations modify external systems and may be irreversible, execution must follow controlled commit protocols rather than direct tool invocation. For that reason, production-grade workflows use staged commits.
The common sequence is:
Generate draft action.
Run policy and permission checks.
Collect required approval tokens.
Commit with an idempotency key and correlation ID.
Verify post-commit system state.
Emit an immutable audit event.
Execution isolation is also a practical requirement. High-consequence commits should go through a dedicated execution service and not directly from your planning code. This makes your rollback logic, compensation paths, and reconciliation workflows easier to enforce and audit.
Idempotency is a non-negotiable detail once tools can write. If retries can happen and commits are not idempotent, you will eventually double-charge, double-close, or double-create. Mature APIs often provide explicit guidance here, including idempotency keys for safe retries. Feel free to refer to the Stripe API idempotency docs to learn more.
When rollback is impossible, you also define compensating actions in advance, such as reverse payment, reopen ticket, notify owner, trigger reconciliation, etc.
10. Coordination Layer
In the Coordination layer, production systems typically move away from a flat swarm and toward a supervisor and worker pattern. That is because flat swarms make ownership, routing, context management, tool permissions, failure handling, and output verification harder to control. The supervisor decomposes and routes work, workers stay tightly scoped with specific tools, and a verifier (or policy gate) blocks progress if outputs do not meet the required contract. This is the shape you see people implement with multi-agent frameworks like LangGraph, AutoGen, or CrewAI.
How all three components work together
Supervisor: assigns tasks
Workers: execute scoped steps
Verifier: enforces contracts between steps
The operational difference between 'a demo' and 'a system' is the handoff contract. If agents exchange only natural language, debugging and governance degrade quickly because you cannot reliably trace who used what evidence, against which state snapshot, to trigger which action. In practice, handoffs become typed message envelopes that at minimum carry a correlation_id, a state_version (so everyone is acting on the same Perception snapshot), evidence references, and an explicit output schema contract.
Do not introduce this layer until single-agent performance is stable, monitored, and measured. Premature multi-agent routing multiplies your failure surfaces before you have controlled the first one.
11. Safety, Security, and Governance Layer
This layer is not one filter at the top. It is a distributed set of controls across intake, retrieval, planning, tooling, execution, and output.
Again, OWASP's LLM risk taxonomy is useful here because it maps directly to runtime controls, and it is especially direct about agentic risk patterns like Excessive Agency.
A practical mapping looks like this:
Prompt injection: input isolation, tool permission gates, and pre-action policy checks.
Sensitive information disclosure: retrieval ACL, output redaction, and DLP checks.
Excessive agency: action class enforcement, scoped credentials, and approval requirements.
Unbounded consumption: token, rate, and budget guards.
Your Safety, Security, and Governance layer is what helps you avoid scenarios like Air Canada that we previously discussed. If your system can say the wrong thing and you remain accountable, then your system can also do the wrong thing, and you remain accountable. Governance is the runtime control that safeguards you.
12. Observability and Evaluation Layer
Observability tells you what is happening inside your workflow. Evaluation tells you if the behavior is acceptable to ship.
Every run should carry trace identifiers and capture intake payload, evidence set, plan output, tool calls and responses, policy decisions, and final action outcome. For most enterprises, the practical way to keep this coherent across multiple services is to standardize on distributed tracing and context propagation (for example, OpenTelemetry context propagation).
This enables fast root-cause analysis and defensible audits.
Evaluation needs two loops. An offline regression suite for known scenarios and edge cases, and online monitoring for drift, anomalies, and incident triggers.
As goes with any production environment, leading agentic AI teams do not push prompt, policy, or tool updates straight to full traffic. They use rollout gates tied to evaluation thresholds (OpenAI's agent evals guide).
Note: Since these logs tend to balloon quickly, have a clear strategy regarding how verbose you want your logs to be, as well as the retention/archival policies.
How teams actually operate these components
Architecture fails when ownership is vague. A practical operating model looks like this:
Operations and domain teams own objective semantics and exception rules.
Security and risk own policy definitions and control tests.
Applied AI owns retrieval quality, planning quality, and evaluation design.
Platform engineering owns orchestration runtime, tool gateway reliability, and traces.
This is not overhead. It is the minimum structure for safe automation.
Final thought
The 12 components are enforceable boundaries. When these boundaries are implemented as runtime controls, agentic AI becomes a dependable business infrastructure. When they remain conceptual, the system sounds smart and fails where it matters.
Frequently Asked Questions
An Agentic AI system is an advanced AI architecture where autonomous agents can perceive data, make decisions, and take actions toward specific goals with minimal human intervention. These systems combine reasoning, memory, planning, and execution capabilities.
The key components typically include a perception module (data input), reasoning engine (decision-making), memory (short-term and long-term storage), planning module (task sequencing), and action/execution layer (performing tasks via APIs or tools).
Memory allows the system to retain past interactions, context, and learned patterns. Short-term memory helps with immediate tasks, while long-term memory enables continuous learning and improved decision-making over time.
Planning helps the AI break down complex goals into manageable steps, prioritize tasks, and adapt dynamically based on feedback. This ensures efficient and goal-oriented execution in real-world production environments.



