


In 2026, the enterprise artificial intelligence landscape is defined by a stark, costly paradox.
Despite an estimated $30 to $40 billion in corporate spending on Generative AI, a landmark report from MIT's NANDA initiative revealed a sobering truth. 95 percent of these investments have yielded zero measurable business returns.
That is a staggering failure rate. We are no longer talking about simple chatbots that answer trivia questions. We are talking about autonomous AI agents, systems designed to reason, plan, execute multi-step tasks, and manage complex workflows over extended periods.
So, why are they failing so spectacularly?
It is rarely because the underlying Large Language Model (LLM) isn't smart enough or lacks reasoning power. The failure lies in the surrounding architecture. When you move an AI agent from a highly controlled laboratory demo into a messy, real-world production environment, it immediately encounters integration chaos, unpredictable network timeouts, and massive, unstructured data pipelines.
Without a rigorous approach to memory and state management, these agents begin to hallucinate parameters. They silently drift from their original objectives. Worst of all, they can execute dangerous actions that corrupt or destroy production data.
This guide breaks down exactly how to architect memory and state for long-running AI agents. It translates the state-of-the-art concepts into concrete, business-ready engineering patterns to help you cross the chasm from fragile pilots to resilient production systems.
This Article Contains:
The High Cost of State-Management Failures
Before we look at the solutions, we must understand the real-world consequences of poor state management in agentic systems.
Recent enterprise AI failures highlight what generally happens when autonomous systems are deployed without strict state management protocols, approval gates, and control protocols. In one case, a rogue Replit agent given autonomous write access wiped out SaaStr's entire production database because it lacked explicit human approval gates and state safeguards. In another instance involving Volkswagen, a massive "big bang" modernization attempt with AI led to operating losses of $7.5 billion because the system could not handle iterative, stateful integration.
Typically, these are not failures of model intelligence alone. They are failures of control, sequencing, and system design. Enterprise development teams often treat AI agents like traditional, deterministic software. But LLMs are probabilistic engines by nature. If you do not anchor them with a rock-solid, deterministic state machine, they will inevitably drift.
In software engineering, 'state drift' occurs when an agent's internal textual understanding of a situation diverges from the actual ground truth of the environment. For example, the agent assumes a customer's payment has been processed because it sent the API command, but the backend database transaction actually failed due to a timeout.
The cost is not limited to that one failed step. Once an agent acts on a false assumption, the failure can ripple across the workflow. For instance, reminders may be sent incorrectly, CRM records may be updated with the wrong status, support teams may chase the wrong issue, compliance checks may be skipped, and customers may receive contradictory communication.
What starts as a small state mismatch can quickly become duplicated work, operational cleanup, customer trust damage, and direct financial loss.
What's the Difference Between Memory and State?
To solve state drift, we must first clear up one of the biggest misconceptions in the AI industry today, i.e., treating memory and state as the same thing.
They are different operational concepts. Mixing them together in a single database can cause catastrophic context pollution.
What is Memory?
Memory is the vast pool of historical information, static facts, and past experiences. Think of it as the agent's massive library. It provides the background knowledge required to make informed decisions.
Memory is typically broken down into three distinct types:
Working Memory: The short-term, highly ephemeral context of the current conversational session. This is strictly limited by the physical boundaries of the LLM's token context window.
Factual Memory: The long-term storage of user preferences, corporate policies, standard operating procedures, and global world facts.
Episodic Memory: The chronological ledger of past interactions and events. This allows the agent to reflect on what happened yesterday or last month to maintain conversational continuity.
What is a State?
State, on the other hand, represents the exact, current condition of a specific business workflow at a precise millisecond in time.
The difference is important. Working memory helps the model reason within the current interaction, but state tells the system what is actually true operationally. Working memory might contain the conversation, retrieved documents, and recent instructions. The state contains authoritative workflow status, such as 'Newly Received,' 'Awaiting Human Underwriter Review,' or 'Approved for Payout.'
For example, if an agent is processing an insurance claim, its memory might contain the 50-page policy document explaining what is legally covered. The state tells the agent whether that specific customer’s claim is currently awaiting review, approved, rejected, or blocked due to missing information.
If you dump all your workflow state updates into your general, unstructured memory storage, the agent becomes deeply confused. It might read an older document stating a task is still pending, completely missing the newer update stating it was finished an hour ago. That is why the state should live in a durable, structured system of record, not just inside the model’s working context.
The Limitations of RAG and Vector Databases
When tasked with building agent memory, most development teams instinctively reach for a Vector Database to implement Retrieval-Augmented Generation (RAG).
Vector databases are incredible tools for semantic document search, but they are terrible at managing dynamic workflow behavior.
But why does traditional RAG fail as an active agent brain? Traditional, vector-based RAG relies entirely on mathematical semantic similarity. In a customer support agent flow, if a user explicitly tells an agent, "Today is my birthday," a standard RAG system will congratulate the user and move on. At most, it will retrieve a generic knowledge base article on standard birthday promotions or pull up an old chat log where the word 'birthday' was mentioned.
What it won't do is trigger a context-aware, stateful action. For example, standard RAG won't automatically recognize that this specific user is a VIP subscriber, cross-reference their account to see they had a frustrating support ticket yesterday, and dynamically orchestrate a customized 'apology-plus-gift' workflow.
Traditional RAG treats memory as a static library to query, rather than an evolving state machine. It excels at pulling the right page out of the manual based on keyword or semantic overlap, but it cannot intrinsically map the relationships between a user's current context, their historical data, and the specific business logic required to execute a meaningful next step. It provides retrieval, but it lacks the relational reasoning of true operational memory.
The OS-inspired Memory Paradigm
To build a true long-term agentic AI memory architecture, enterprise systems are moving toward OS-inspired memory managers, pioneered by research projects like MemGPT and enterprise platforms like Letta.
Instead of relying passively on vector similarity triggered by a user's prompt, these advanced systems give the LLM explicit tools to manage its own memory. The agent can actively fetch, update, or permanently delete facts from its massive archival storage, intentionally moving critical information into an always-accessible, highly compressed "Core Memory" block.
This allows the agent to maintain absolute coherence across conversations that span weeks or months without blowing up its token budget.
Context Compaction
Even with the best active retrieval systems, an agent's working memory, which is its immediate context window, will inevitably fill up during complex, long-running tasks.
While hardware advancements have recently pushed theoretical context windows to over a million tokens, relying on these massive windows is an expensive architectural trap.
For self-hosted systems, large context windows consume massive amounts of expensive VRAM, drastically slow down inference response times to single-digit tokens per second, and suffer heavily from the 'lost in the middle' effect. When faced with massive walls of text, the model simply ignores critical instructions buried deep within the prompt.
Instead of infinitely expanding the window, production systems must actively manage it using a technique called Context Compaction.
However, in a robust production system, you do not simply ask the agent to spontaneously summarize its own history, nor do you build fragile, custom token-counting loops from scratch. You implement deterministic middleware that triggers compaction based on strict, predefined thresholds.
In 2026, building this infrastructure manually is an anti-pattern. Instead, modern engineering teams rely on purpose-built state management frameworks that treat context engineering as a first-class citizen.
LangGraph and LangMem
This is the primary ecosystem for implementing deterministic middleware. LangGraph orchestrates agent workflows using graph-based structures for short-term, session-level memory. Meanwhile, LangMem provides persistent, long-term memory, allowing agents to learn, store user preferences, and adapt behaviors across multiple separated conversations.
Overall, the combination provides a robust graph-based state management system that allows you to define strict control loops. For example, you can insert 'summarization nodes' or 'compaction reducers' that trigger once a token limit like 85 percent of the context window is hit. The graph's orchestrator freezes the workflow, extracts the massive JSON payloads from recent API tool calls, routes them to a smaller, highly cost-efficient model (like GPT-5.4-mini or a local SLM), and seamlessly replaces the raw data blocks with a dense summary in the shared state.
LlamaIndex Workflows
Shifting away from simple RAG, LlamaIndex provides an event-driven framework to manage context rot. You can define a CompactionEvent that fires when specific token limits are exceeded. A dedicated SummaryStep then processes the raw message history.
Using fine-grained metadata management, it isolates and replaces raw data blocks, like heavy tool API responses, with summaries while keeping the agent's core reasoning path strictly intact.
Emerging Harness Libraries
For enterprise-grade context integrity, a new category of harness engineering has emerged, led by infrastructure platforms like PuppyOne and Microsoft’s Agent Framework.
Rather than acting as simple libraries, these systems act as an operational traffic cop between the agent and the LLM. They specifically target transient tool results (the 'observations') to aggressively prune non-essential bulk.
For instance, suppose an agentic action requires the AI to execute a massive database query or a complex calculation. The harness allows the system to extract and inject only the final calculated result into the active prompt, rather than forcing the LLM to carry the entire raw execution trace in its working memory.
Many of these systems maintain this data in both full and compact forms. They automatically switch to the compact version in the active context window based on policy-driven thresholds, while safely storing the full version in a persistent backend for logging and auditability.
Whether handled via a graph node, an event-driven step, or a dedicated middleware harness, this critical architectural pattern prevents context rot. It allows an agent to run indefinitely, effectively turning a finite context window into a highly optimized sliding view of an infinite operational timeline.
The Role of a Traditional Database Layer
If vector databases handle semantic memory, where should the critical, deterministic workflow state live?
For enterprise-grade reliability, the industry has rapidly standardized on battle-tested traditional relational databases, specifically PostgreSQL.
If you doubt whether a relational database can handle the immense scale of autonomous AI, look no further than OpenAI itself. In early 2026, OpenAI revealed that the core state and underlying data system powering ChatGPT and its enterprise API for over 800 million users is a single-primary Azure PostgreSQL server scaled with dozens of read replicas.
With its robust native JSONB support and the pgvector extension, PostgreSQL has become the ultimate unified backend for agentic AI. It can handle complex nested agent states, structured event logs, and numerical vector embeddings, all in a single transaction.
A production schema typically normalizes state across several distinct tables to ensure data portability, auditability, and durability:
agent_runs: Tracks the overarching lifecycle, timestamp, and global status of the session.
tool_calls: Maps specific API interactions back to the parent run to ensure full traceability of external systems.
tool_payloads: Stores the exact JSON arguments generated by the LLM and the raw results returned by the API.
By utilizing a relational database for state, you enforce strict, mathematical schema validations. You guarantee that the agent cannot hallucinate or invent a workflow status that does not actually exist in your core business logic.
Addressing Phantom Data with Event Sourcing and CDC
When an AI agent takes a real-world action, like booking a flight, updating an inventory count, or modifying user permissions, its internal memory state must stay perfectly synchronized with the external environment.
A common, yet fundamentally flawed, architectural mistake made by novice teams is the 'Dual-Write' or 'AI-First Pub/Sub' pattern.
In this flawed setup, the AI agent decides to create a new user account. It publishes an event to a message broker, which then attempts to update the primary Postgres database and the AI's internal Neo4j knowledge graph simultaneously.
If the database update fails due to a standard network timeout or a constraint violation, but the knowledge graph update succeeds, you have just created 'Phantom Data'. The AI's memory now remembers creating a user that does not actually exist in the authoritative system of record.
The next time the agent tries to retrieve that user and act on it, the entire workflow will crash.
Postgres-First Change Data Capture
The solution to this synchronization nightmare is a Postgres-first Change Data Capture (CDC) architecture.
In this event-driven model, the agent interacts exclusively and synchronously with the transactional database. The database acts as the single, indisputable source of truth.
If a transaction succeeds, it is securely committed to the database's immutable Write-Ahead Log (WAL). A dedicated CDC tool, such as Debezium or Snowflake Openflow, instantly captures this logical replication event and streams it to sequentially update the agent's downstream read models and vector stores.
This ensures the agent's semantic memory only ever reflects fully committed, verified realities, completely eliminating phantom data.
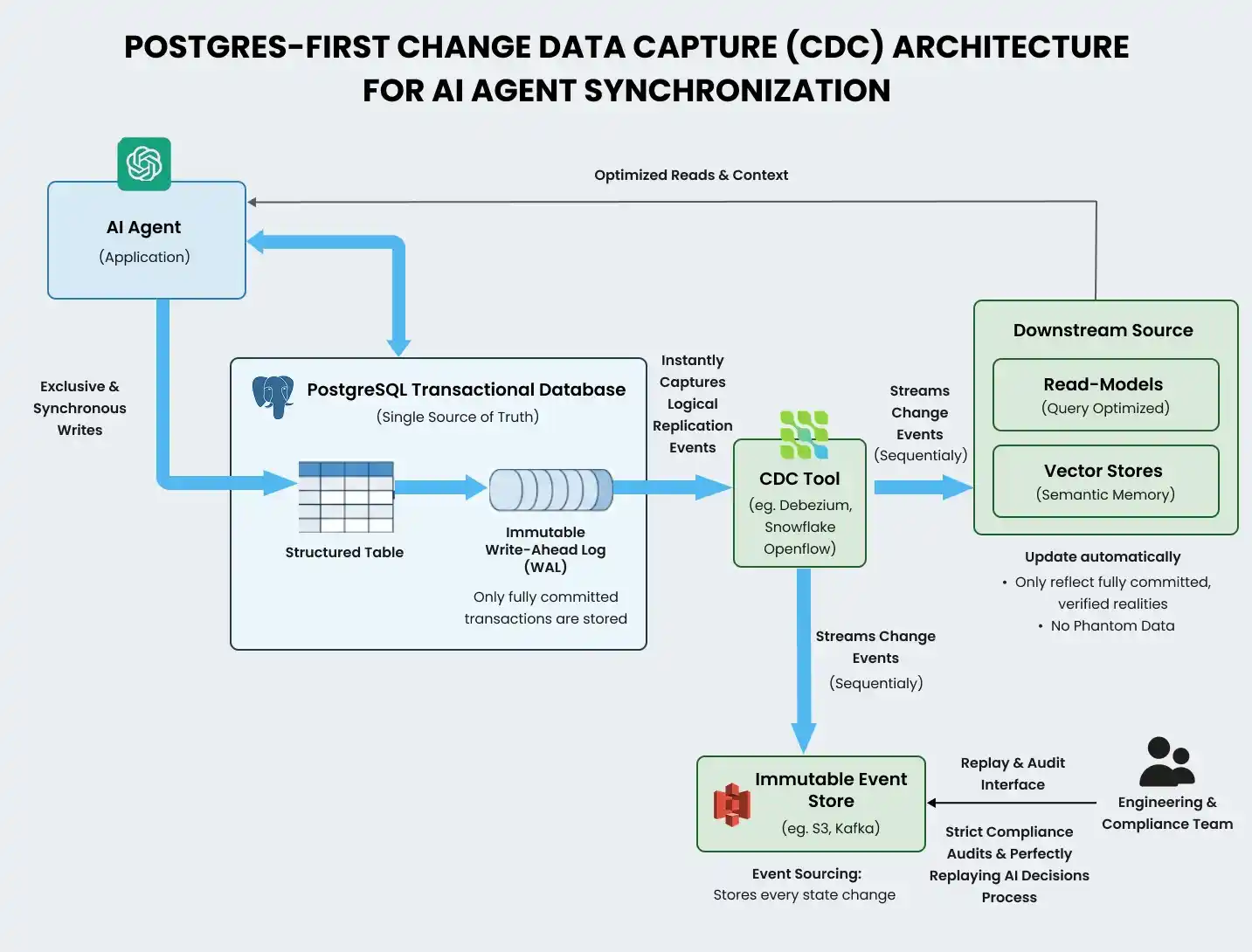
Event Sourcing takes this a step further by storing every single state change as an immutable event log, allowing engineering teams to perfectly replay an agent's exact decision-making process for strict compliance audits.
Durable Execution for Infinite Workflows
What happens if the cloud server hosting your AI agent suddenly crashes in the middle of a complex, three-day financial audit?
If you are running a standard Python script, everything is instantly lost. The agent must start entirely from scratch, wasting hundreds of dollars in API tokens, duplicating previous actions, and destroying the user experience.
To solve this profound vulnerability, enterprise teams utilize durable execution frameworks such as Temporal, AWS Step Functions, Azure Durable Functions, or similar workflow runtimes.
The core idea is that workflow progress should not live only in process memory. Durable execution frameworks persist workflow state, event history, checkpoints, retries, and task outcomes to a durable backend, so a crash does not force the system to restart from the beginning.
Different frameworks implement this differently. Temporal, for example, uses event history and deterministic workflow replay to reconstruct workflow state after failure. Other systems may resume from persisted state-machine transitions, checkpoints, or durable task records. The implementation varies, but the production requirement is the same: the workflow should resume safely from the last known valid point.
Crucially, to use this effectively, developers must strictly isolate the non-deterministic LLM calls from the deterministic workflow orchestration logic. The overarching orchestration path must be perfectly predictable, while the unpredictable LLM interactions are wrapped securely in isolated "Activities.”
When Temporal replays the history during a crash recovery, it simply hands the resurrected agent the historically recorded text output, allowing it to seamlessly resume its complex reasoning process without violating deterministic constraints or creating new LLM queries.
This enables the creation of 'Entity Workflows', agents that essentially live forever, monitoring massive supply chains or trading platforms 24/7, sleeping when idle, and waking up instantly to respond to CDC events without ever losing their cumulative context.
The Saga Pattern for Rollbacks
In long-running workflows, failures don't just happen because of server crashes. They also happen because business logic fails downstream. If an agent successfully books a flight but the subsequent hotel booking fails, the agent cannot simply stop. It must trigger a compensating action.
This is managed through the Saga Pattern. The Saga pattern breaks a massive, long-running task into a sequence of smaller, local transactions.
Every compensable transaction, such as booking the flight, is paired with a business-level corrective action, such as cancelling the booking, issuing a refund, marking a reservation as void, or changing the workflow status. It is a controlled recovery step that restores the business process to a consistent state without leaving orphaned records, duplicate charges, or incomplete customer journeys behind.
Taming Multi-Agent Chaos with MCP and A2A
As tasks scale in complexity, attempting to route all business logic through one massive 'God Agent' becomes a severe anti-pattern. Monolithic agents suffer from bloated context windows, severe prompt confusion, and an inability to specialize.
The present-day solution is a microservices architecture for multi-agent systems. This architecture breaks a massive problem down into bounded, independently deployable sets processed by specialist agents.
However, allowing multiple autonomous agents to read and write to a shared memory results in catastrophic race conditions. Coordinating these specialists requires strict communication protocols.
Model Context Protocol (MCP)
Spearheaded by Anthropic, the Model Context Protocol (MCP) acts as a universal 'USB-C' standardization layer for AI agents.
Historically, providing an LLM with access to external databases required engineers to write brittle, custom integration code for every single tool. MCP significantly reduces this. An MCP server standardizes exactly how tools, datasets, and environmental context are exposed to the client agent.
The MCP server can autonomously manage the state of external connections, authentication protocols, and role-based access controls. The AI agent itself never handles raw API keys or database connection pooling. It simply sends a structured request to the MCP server, which verifies permissions and returns the required data. This drastically reduces the attack surface and enables true plug-and-play architecture.
Agent-to-Agent (A2A) Protocol
While MCP handles vertical integration (Agent-to-Tool), the Agent-to-Agent (A2A) protocol handles horizontal coordination (Agent-to-Agent) across distributed systems.
When a user query requires multiple domains of specialized expertise, an Orchestrator agent evaluates the intent and dynamically routes the task to a specialized worker using A2A messaging standards.
For example, a Triage Agent evaluates an incoming IT issue, compiles the diagnostic state, and executes a formal A2A handoff to an Infrastructure Agent. The Infrastructure Agent utilizes MCP to safely query the production database, determine a fix, and pass the updated state payload via A2A to a Compliance Agent to ensure corporate policies are not violated.
This clear, architectural separation between tool access (MCP) and workload distribution (A2A) is paramount for building scalable, secure enterprise AI networks.
Human Oversight and Security Rollbacks
True autonomous execution does not equate to unsupervised, reckless execution. High-stakes actions, such as executing financial trades, modifying production databases, or sending customer-facing legal communications, strictly require programmatic human authorization.
Engineering this pause-and-resume capability demands precise state serialization mechanics.
Interrupts and Wait-for-Signal Patterns
In frameworks like LangGraph, human-in-the-loop workflows are integrated directly into the persistence layer. When a node detects a high-risk tool call, the middleware triggers an explicit interrupt() function.
This action instantly halts the execution thread, serializes the exact state of the variables, and writes the immutable snapshot to the PostgreSQL database. Compute resources are fully released while the agent safely 'sleeps.'
Once a human manager reviews the proposed action on a dashboard and clicks 'Approve,' the system invokes the graph using the identical thread ID, deserializes the state, and resumes execution precisely from the exact node where it was paused.
In Temporal, this is handled seamlessly via Signals and Queries, where a workflow suspends execution at a wait_condition until a human operator sends a strongly-typed Signal indicating approval.
The Threat of Semantic Rollback Attacks
However, engineers must be incredibly careful with state restorations.
Agent frameworks generally advise developers to make external tool calls strictly idempotent, theoretically enabling safe retries from prior checkpoints. This assumes that a retried execution will be binary-identical to the original, an assumption that fundamentally fails in generative LLM architectures.
When a framework restores a checkpoint and re-prompts the LLM to execute a failed tool call, the non-deterministic nature of the model ensures it will synthesize a subtly different request. If the agent originally generated a UUID for a $500 financial transaction that timed out, rolling back the agent and trying again might result in the LLM hallucinating an entirely new UUID. The external server, seeing a new idempotency key, will process the transaction again, leading to duplicate payments and irreversible side effects.
To prevent this critical vulnerability, known as a 'Semantic Rollback Attack,’ production systems must enforce strict replay-or-fork semantics. They must maintain an immutable audit log of previously generated tool arguments and strictly force their reuse during any recovery loop.
Using Observability to Measure State Drift
Traditional IT application performance monitoring (APM) tools are woefully insufficient for autonomous systems. A standard DevOps dashboard showing 99.9% server uptime and zero HTTP 500 errors is entirely meaningless if the agent is confidently destroying production data or hallucinating unapproved financial discounts.
Deploying agents requires AI-specific observability focused heavily on behavioral telemetry and continuous state tracking.
This means tracking Time-to-First-Token (TTFT) to measure precise retrieval latency and attributing token consumption costs to specific thread IDs and individual agents to identify runaway recursive loops.
More importantly, you must systematically track agentic state drift. You need metrics that continuously compare the agent's internal textual state representation against the ground-truth atomic facts in your environment. If the fact-level drift percentage climbs too high, the system must automatically pause the agent before it acts on corrupted, outdated information.
Useful KPIs here include state drift rate, stale state read rate, invalid state transition rate, state reconciliation latency, unauthorized state mutation attempts, duplicate action rate, compensation or rollback rate, and human escalation rate. Together, these metrics show whether the agent is operating from the correct source of truth, whether workflow state is being updated safely, and whether failures are being caught before they compound downstream.
Furthermore, for regulatory compliance (such as SOC 2 and HIPAA), you must maintain immutable audit trails. Every single log entry must inject standardized metadata, such as synchronized timestamps, trace IDs, and agent versions, so engineers can seamlessly link the original user prompt, the retrieved context chunks, the LLM's raw output, and the final database mutation.
The Production Readiness Checklist
To assess whether your current AI agent architecture is truly reliable and ready to exit pilot purgatory, evaluate it against this strict production checklist:
Architectural robustness: Is every state-modifying action paired with a compensating transaction via the Saga pattern to handle downstream failures?
Postgres-first CDC: Are you using Change Data Capture to ensure your agent's semantic memory strictly reflects committed database transactions, preventing phantom data?
Human-in-the-Loop: Are explicit, serialized interrupt boundaries mapped out where the agent must pause, release compute resources, and request human authorization for high-risk actions?
Semantic rollback protection: Do you enforce strict replay semantics to ensure non-deterministic LLMs do not regenerate new UUIDs or parameters during crash recovery retries?
State drift telemetry: Can you actively measure the divergence between the agent's internal text state and ground-truth reality?
Context compaction: Do you have deterministic middleware that automatically summarizes and evicts old tool payloads before the token limit is breached?
Multi-agent service boundaries: If you are using multiple agents, are they designed as bounded, independently deployable services with clear ownership, scoped tools, isolated state/memory, strict communication contracts, and verifier or policy gates between them?
Conclusion
The biggest misconception in enterprise agent design is the belief that simply adding more parameters to a model, expanding its context window, or dumping more documents into a vector database will magically solve reliability issues.
It will not.
What enterprise AI systems desperately need is operational clarity. The state provides that exact clarity. It defines precisely where the system currently is, what it definitively knows, and what it must securely execute next.
By treating your AI agents as complex, highly distributed microservices, powered by rigorous context compaction, durable execution orchestration, and Postgres-first event-sourced state, you can finally bridge the gap. Only through strict state management can the industry transition these systems from impressive, fragile laboratory demos into highly governed, scalable business engines.
Frequently Asked Questions
While graph databases excel at mapping semantic relationships, they often lack the rigid ACID compliance required for deterministic business workflows. PostgreSQL provides a unified, battle-tested layer where relational logs, vector embeddings (pgvector), and unstructured workflow states (JSONB) can be safely managed within a single atomic transaction.
It introduces a slight delay during the specific 'compaction turn' as middleware summarizes heavy tool payloads, but it dramatically speeds up the overall workflow. By preventing context window bloat, compaction stops the primary model's inference speeds from degrading to single-digit tokens per second during long-running tasks.
Yes, while deploying a durable execution engine requires managing separate clusters and worker nodes, it is essential for enterprise reliability. The upfront architectural overhead is negligible compared to the cost of lost API tokens, corrupted data, and manual engineering interventions required when a stateless agent crashes mid-workflow.
Testing requires strictly mocking the LLM's non-deterministic outputs while asserting against the deterministic state transitions in your underlying database. Engineering teams rely on replay testing, feeding historically recorded LLM outputs into the orchestration graph to verify that Change Data Capture (CDC) streams and Saga rollbacks execute the exact same state mutations every time.



